Azure IoT Edge on constraint devices
In this post I would like to show some tweaks you can (and might need to) apply to influence the behavior of your IoT Edge device, when it comes to message retention on devices that are limited in resources.
The setup of this scenario is not uncommon, as it uses a module to retrieve telemetry from machines, parses them in another module and sends the messages to an IoT Hub.
The problem
After a while the device is not sending data anymore and is not accessible via SSH. The logs reveal lots of message still in the queue.
But why? And how can I find out what causes the problem?
Spoiler: Disk full 🙁
Troubleshoot
Looking at logfiles helps a lot – if you have access to the logfiles. Fortunately IoT Edge can expose data in the Prometheus exposition format for the edgeHub and edgeAgent. These endpoints are enabled by default for IoT Edge 1.0.10 (upgrade to this version if you haven’t) and can be enabled for 1.0.9.
The data can then be uploaded to Log Analytics for further analysis and to create alerts with a sample metrics-collector module.
For analyzation and to display the metrics, you can use a Workbook in Azure Monitor.
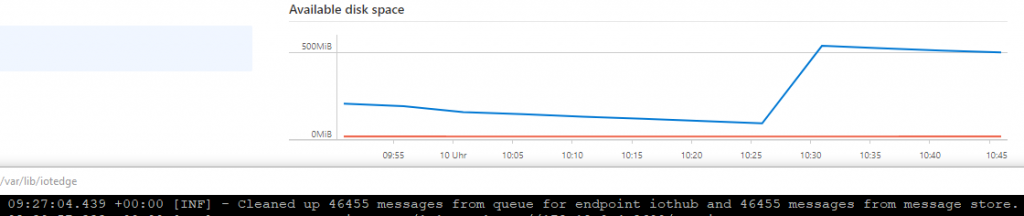
In this particular case I could see that the available disk space was going down, down, down until the whole device did not respond anymore (no SSH access possible, no data sent to Azure).
What to change?
Adding more space to the disk was not an option. Other solutions needed to solve the issue. There are 2 options I looked at and adjusted to be a better fit for the usage scenario and resource limitation.
- The Time to live setting defines how long messages will be kept on the device: Operate devices offline – Azure IoT Edge | Microsoft Docs (which is set to 2h per default).
- The not so obvious Rocks DB size configures the size of the logfiles: https://github.com/Azure/iotedge/issues/2431#issuecomment-582089419
After tweaking the settings, the following graph shows that now the device cleans up data before the disk runs full.
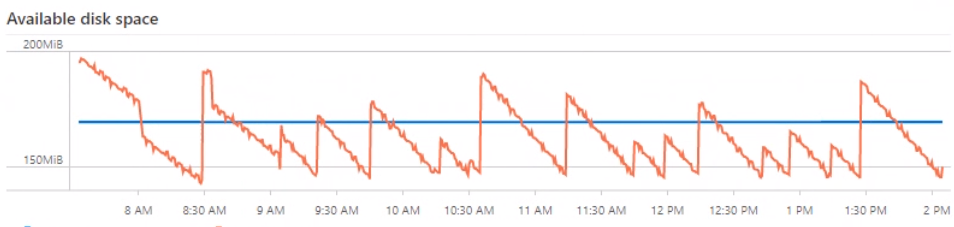
I can not give you values for you particular setup. You’ll need to figure them out for your setup depending on the amount of messages going though the Edge device and hardware sizing. Here are some pointers to settings which you might want to investigate, if you hit a similar problem on your devices:
- Time-to-live: iotedge/Route_priority_and_TTL.md at master · Azure/iotedge (github.com)
- Set the used protocol (MQTT/AMQP/HTTP): Prepare to deploy your solution in production – Azure IoT Edge | Microsoft Docs
- Place limits on log sizes: Prepare to deploy your solution in production – Azure IoT Edge | Microsoft Docs
- Alternate cleanup of message store: Alternate cleanup processor for MessageStore by dylanbronson · Pull Request #2893 · Azure/iotedge (github.com)
- Optimize for performance will allocate larger files upon usage. Disabling might help:
iotedge/EnvironmentVariables.md at master · Azure/iotedge (github.com)
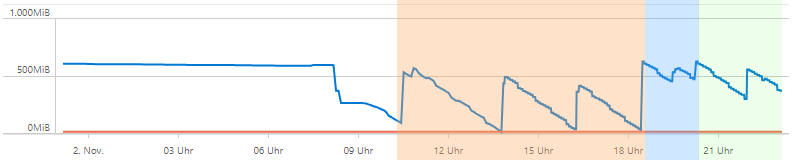
The above image shows setting for RocksDB (orange: 512MB, blue, 128MB, green 256MB). With the default setting the device is running out of disk space.
What can I do to prevent the device crashing?
Well, it depends 🙂 You can find a setting from the above that will prevent a full disk for a known scenario. But if you don’t know which modules with which setting is deployed?
In this case an alarm for low disk space is an option. It then needs to trigger a function that calls a method on the device to restart the edgeHub. This will clear the cache.